# MIMO-UNet
收录于 2021ICCV,
原文:《Rethinking Coarse-to-Fine Approach in Single Image Deblurring》
源码:GitHub - chosj95/MIMO-UNet: MIMO-UNet - Official Pytorch Implementation
# 网络架构

# 3. 方法论
# 3.1. 多输入单一编码器
首先,非原尺度也就是低尺度的图像在输入到 Encoder(后称 EB)会先进行预处理,特征提取 SCM (shallow convolution module),结构如下,

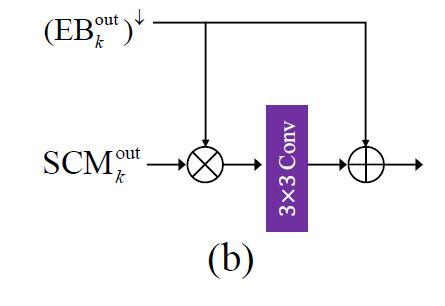
然后,再将 SCM 提取的特征和上一个尺度的 EB 结构进行降采样再融合(这里的融合是指对应元素相乘,然后传递给 3x3 的卷积),输出的结果认为是包含了 “去模糊补充信息” 的特征,再交给后置的残差层(8 个)进行进一步的细化。
# 3.2 多输出单一解码层(可改)
解码层 Decoder(下称 DB)与编码层 Encoder 类似也会融合不同尺度特征。首先,最低尺度只是传递当前尺度的特征,其次,其他尺度的处理层需要将当前尺度特征与 AFF 融合特征(AFF 是将其他尺度特征进行融合的模块,至于为什么最后一个尺度不采用,是因为原本的 U 型结构已经相当于将前面尺度进行融合了,因此添加了 AFF 之后就相当于有了 3 个平行的编解码器进行作用,个人理解,建议结合下面 AFF 公式和网络架构进行理解)进行合并。过程如下公式,
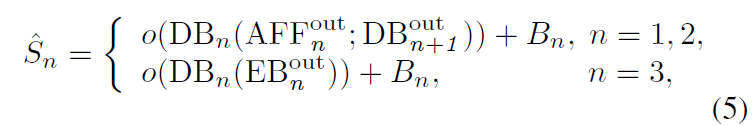
这里的 Decoder 输出是特征图,而非图像,因此 o 是把特征图转为图像的处理(这里采用的单一卷积层)。
# 3.3 综合特征融合 AFF
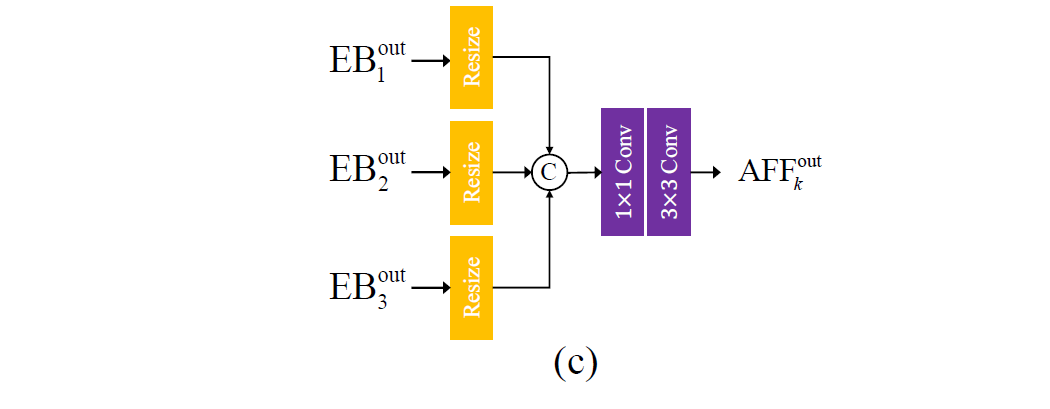
这里是作者的创新点,之前的 coarse-to-fine 去模糊方法,仅使用了低尺度特征作为更细尺度的修正,弹性更小。
(论文 pdf 笔记上有相关改进想法)
受启于尺度内的 dense connection [13],提出 AFF (Asymmetric feature fusion),方式上面已讲,公式如下,
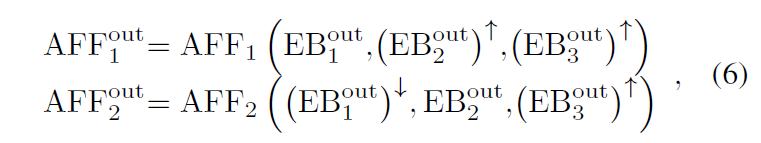
再将,AFF 输出结果传递给 DB,因此 DB 可以利用多尺度特征,进而提升去模糊效果。
# 个人对网络整体看法
首先,整体的网络看起来没有特别深,把 3 个 Ecoder-decoder 结构合并为 1 个,并且 Encoder 前置的 shallow 预处理和 Decoder 前置的合并调整层,AFF 合并后调整层都用少量的 1x1conv 和 3x3conv 的组合,应该整体参数量比较少,并且训练速度很快。应该还有比较大的可改进空间。
# 3.4 损失函数
首先,作者发现 L1 损失比 MSE 损失的效果要好针对他们的网络。
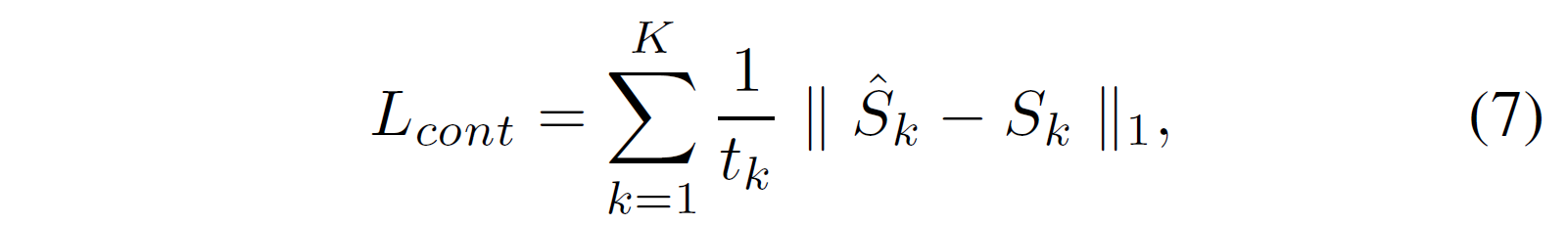
另外,近期研究表明 auxiliary loss terms(辅助损失项,来自《GoogleNet》一文,针对深层网络梯度消失问题而影响整体网络学习速度,方法是将中间层设置分支输出 conv+FC+softmax 结构,再对最终损失和分支损失进行重分配权重和)对网络效果有提升。(参考:GoogLeNet 的实现_liupc 的学习笔记 - CSDN 博客)
auxiliary loss terms 作者认为,可以最小化输入输出特征空间之间的距离,而 deblurring 是恢复高频域损失内容的过程,因此应减小高频空间之间的差距。
作者提出新的损失函数 multi-scale frequency reconstruction(MSFR),即 L1 多尺度频域损失:
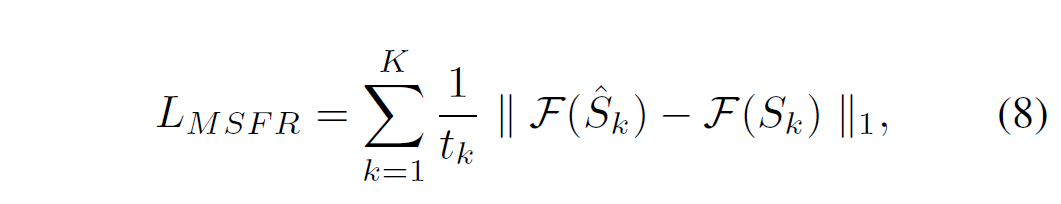
F 表示 FFT(快速傅里叶变换),最终损失设置为:
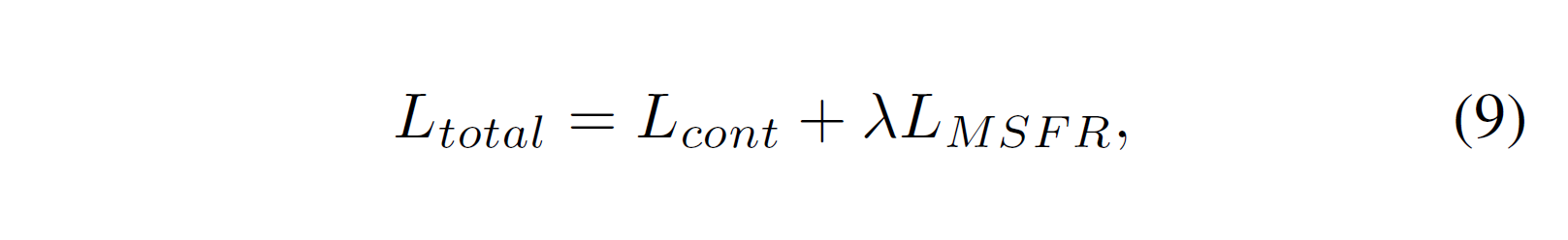
lamda=0.1